R eksempler
Norske bokstaver (æøå) i Rstudio og R
Dette er en forklaring på hvordan man kan få R og Rstudio til å fungere med norske bokstaver.
R-kurs 1: Enkel databehandling med tidyverse
Denne posten baserer seg på et kort kurs jeg holdt som introduksjon til R og Tidyverse. Posten inneholder slidene fra presentasjonen og går igjennom ulike deler av databehandling med dplyr. Posten tar både opp bruken av pipe "|>" og ulike sentrale "verb" fra dplyr slik som "filter", "mutate" og "summarize".
Kommunenummer
Jeg bruker altfor mye tid på å koble nye og gamle kommunenummer. Her er en csv-fil med kommunenavn og -nummer fra før og etter fylkesendringen i 2024.
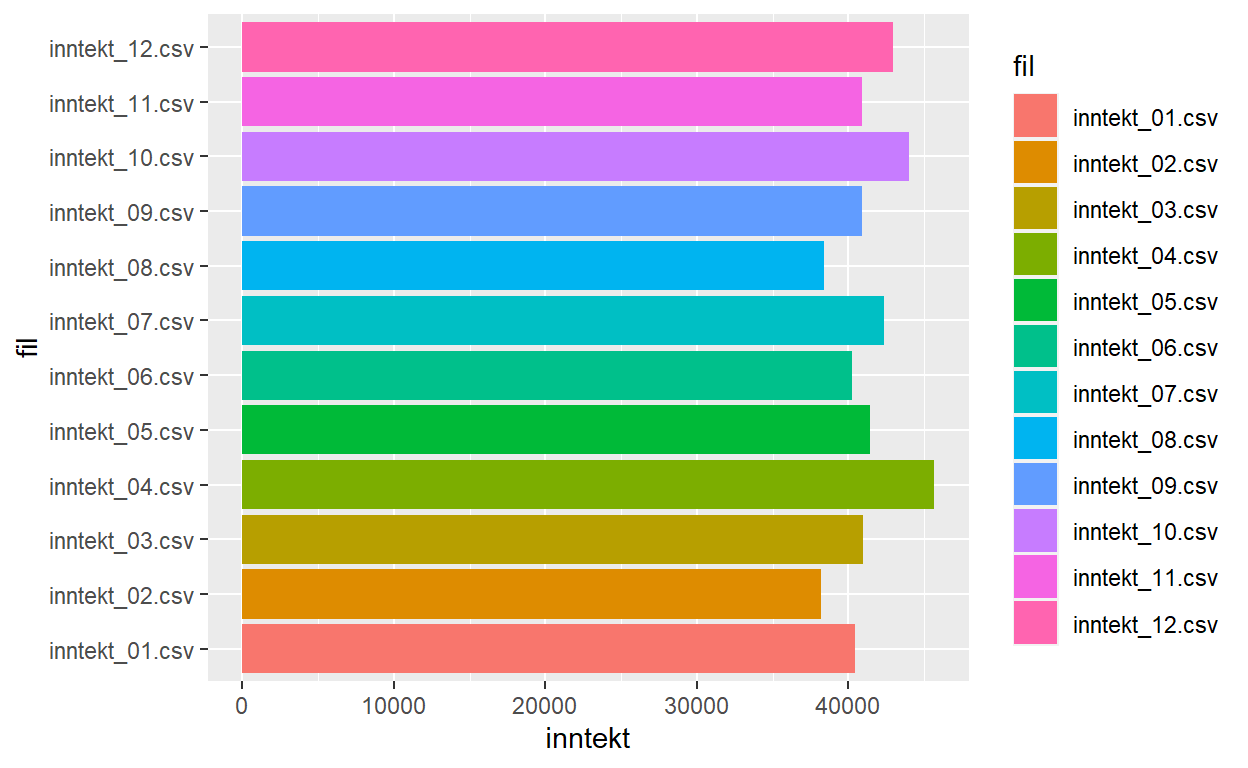
Kan man bruke chatboter til å lage figurer i R?
Terskelen for å ta R i bruk er høy. Det er mye å sette seg inn i før man kan bruke R på en god måte. En av fordelene til R er at det finnes gode verktøy til å lage avanserte figurer. Denne posten viser hvordan chatgpt, bing med flere kan brukes til å få koden som lager figurer.
Hvordan kan man lage en for loop eller for løkke i R?
Denne posten beskriver hvordan man kan lage for loops eller for løkker i R. Dette er en enkel, men litt tidkrevende måte å få gjort ting mange ganger på.
Introduksjon til data.table
Denne posten baserer seg på en presentasjon jeg gjorde av `data.table`-pakka. Den beskriver hvordan man kan bruke `data.table` i R for å jobbe med store datasett slik som registerdata. Posten går blant annet gjennom de ulike posisjonene i klammene `[i,j,by]` og viser hvordan man kan lage nye variabler i `data.table` med `:=`.
Fjerne advarsler og meldinger fra en RMarkdownfil
Når vi jobber i RMarkdown slik som i Quarto vil vi ikke alltid ha alle feilmeldingene med i det endelige dokumentet. I denne posten går jeg gjennom hvordan man kan spesifisere hvilke typer meldinger man vil ha med i den endelige fila. Jeg viser både hvordan man kan bestemme dette for hver chunk og hvordan man kan spesifisere det for hele dokumentet.
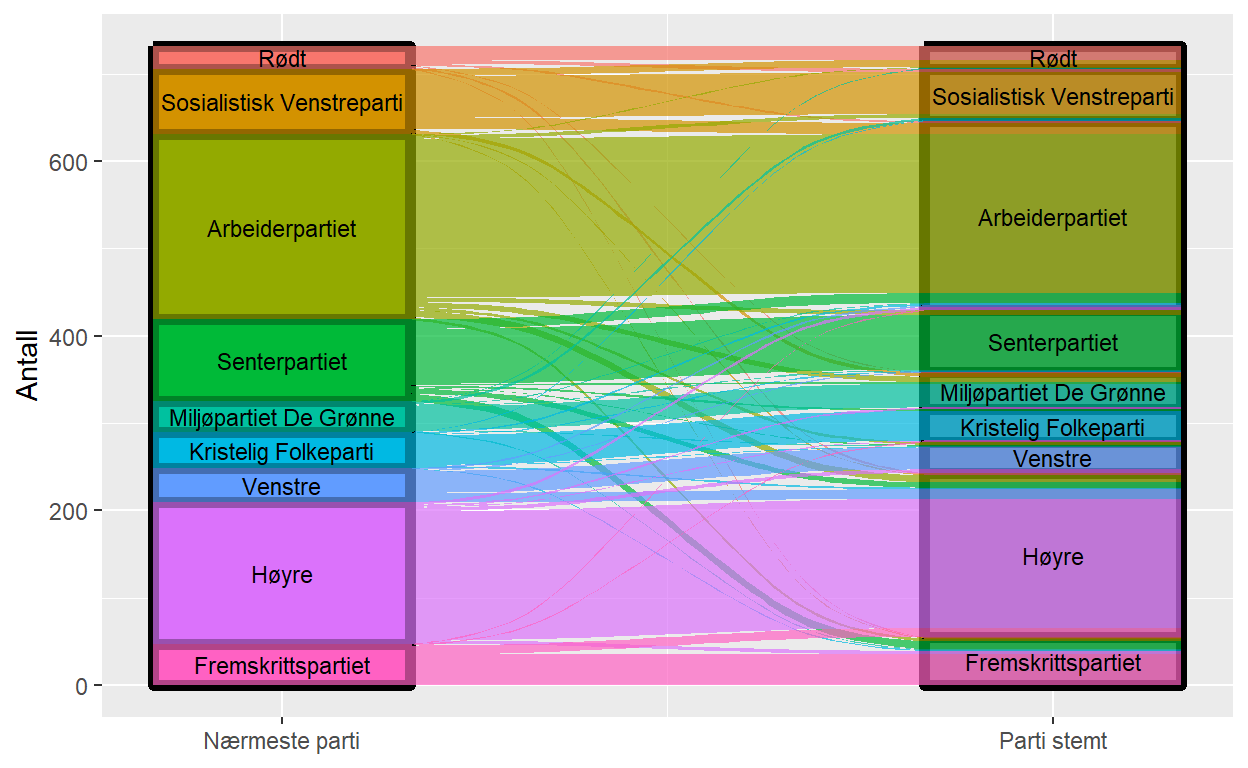
Flytdiagram eller sankeydiagram i R
Denne posten beskriver hvordan man kan lage et flytdiagram også kalt sankeydiagram i R. Dette er en type diagrammer som viser hvordan individer eller grupper beveger seg mellom ulike statuser. Eksempelet er hvordan personer kan oppleve et parti som nærmeste parti, men ha stemt på et annet.
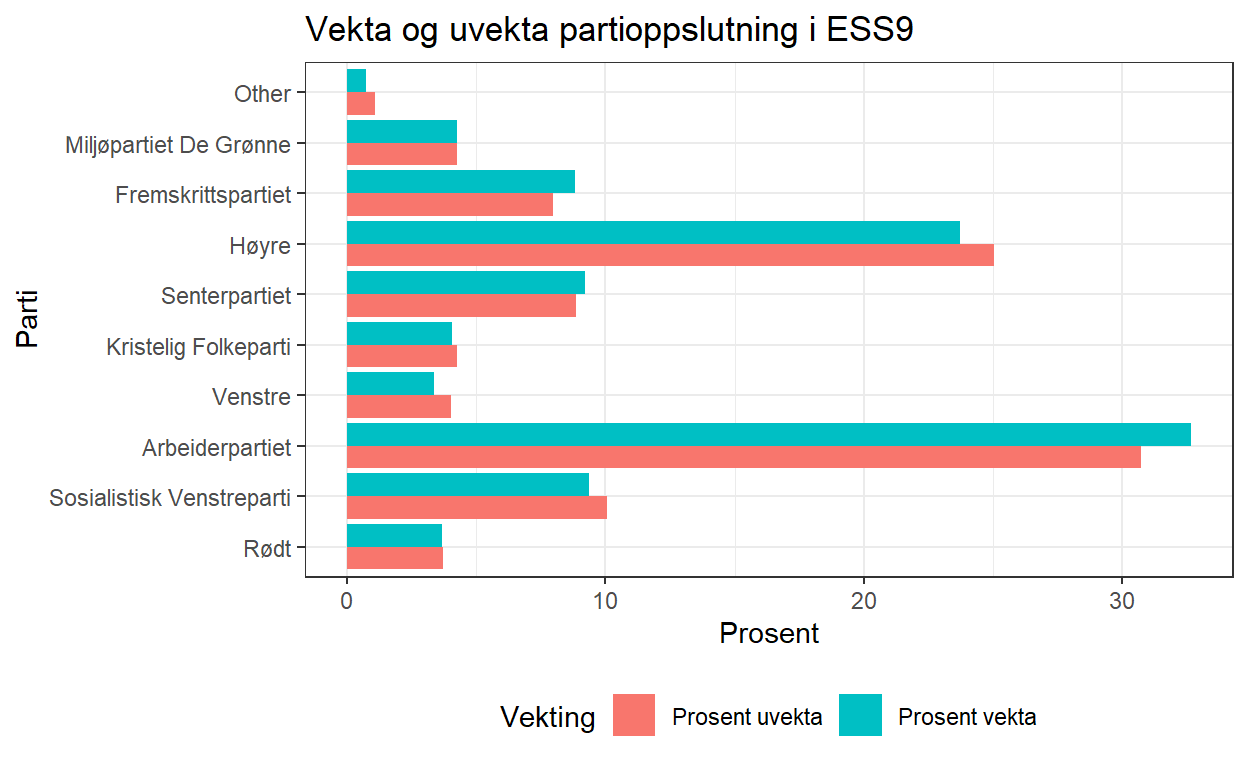
Data med vekter i R
Denne posten beskriver hvordan man kan bruke vekter i R ved hjelp av srvyr- og survey-pakkene. Srvyr-pakka gjør der enkelt å få ut vekta estimater slik som gjennomsnitt og andeler og gjør det enkelt å jobbe med surveyer og spørreundersøkelser. Srvyr bruker ganske standard tidyverse- og dplyr-kode og gjør det mulig å bruke pipe. Dermed blir det mye enklere å få vekta estimater i R.
R-kurs 1: Hvordan komme igang med R
Denne posten er slidene til et veldig kort kurs jeg holdt på ISF for nybegynnere i R. Jeg har ikke skrevet ut kurset, så dette er bare punktene fra presentasjonen jeg brukte og koden i chunkene.
Robuste standardfeil
Denne posten beskriver hvordan man kan beregne robuste standardfeil i R.
Hvordan gjøre en liste til en tabell (data.frame) i R?
Denne posten beskriver hvordan man kan hente ut informasjonen fra en nestet liste i R der data er plassert på ulike nivåer. Først beskrives det hvordan vi får en oversikt over innholdet i lista med str(). Deretter brukes funksjonen `hoist()` for å få ut dataene i en `data.frame` eller en `tibble`. Dette er ofte nyttig når vi har data fra et API eller en nettjeneste.
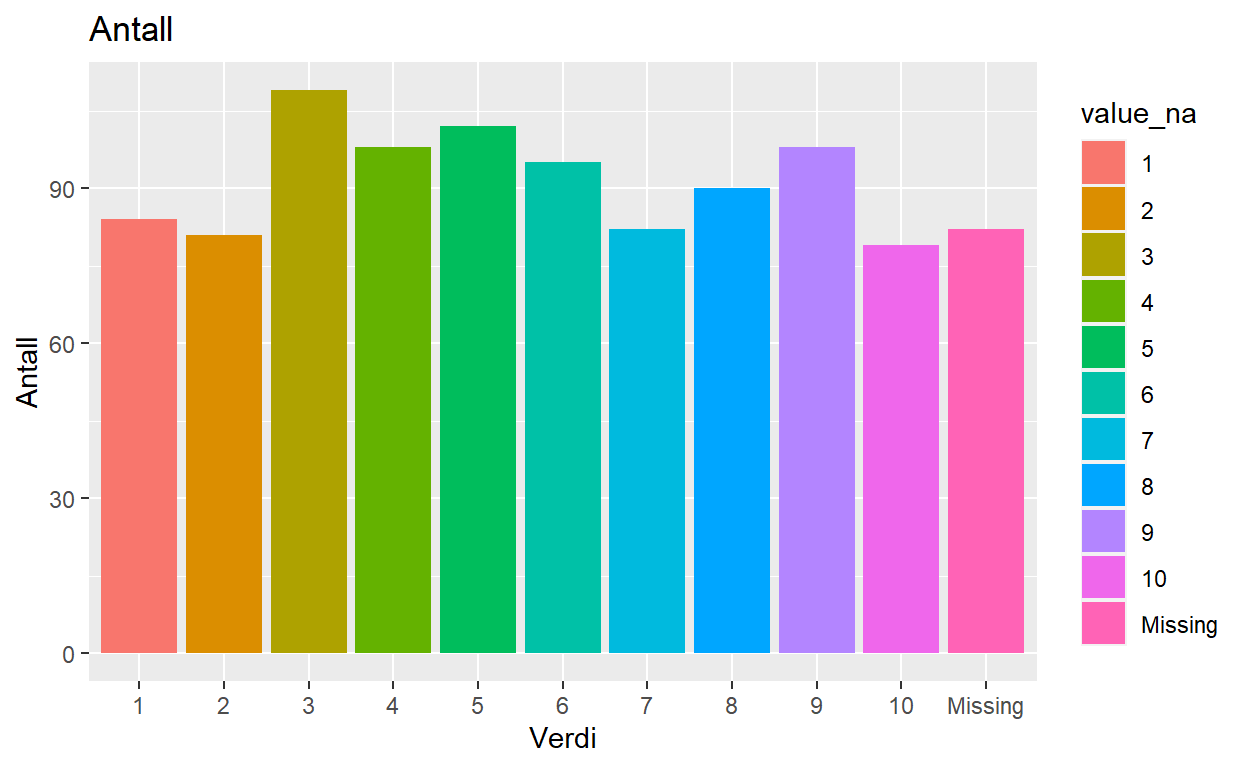
Figur med missing
Denne posten beskriver hvordan man kan lage en figur over en variabel der man tar antall/prosent av hver kategori som også inkluderer missing.